« Espace de noms réseau » : différence entre les versions
m →Phase de test : Correction de fautes d'orthographe. |
Ajout de la méthode "nsenter". |
||
| (Une version intermédiaire par le même utilisateur non affichée) | |||
| Ligne 46 : | Ligne 46 : | ||
* '''privé''': espace de nom concerné par l'exécution (noté ''PID'' dans les pages de ''man'') | * '''privé''': espace de nom concerné par l'exécution (noté ''PID'' dans les pages de ''man'') | ||
* '''ip a''': Commande que l'on aurai tapé normalement pour lister la configuration des interfaces réseaux | * '''ip a''': Commande que l'on aurai tapé normalement pour lister la configuration des interfaces réseaux | ||
Il est également possible d'entrer dans l'espace de nom pour y exécuter les commandes standards de façon tout à fait normal (sorte de ''chroot'') avec la commande suivante: | |||
nsenter --net=/var/run/netns/privé | |||
''Note: la commande <source lang="bash" inline>exit</source> ou le traditionnel <source lang="bash" inline><ctrl>+<d></source> permettent d'en sortir.'' | |||
Comme expliqué plus haut, la configuration de l'interface déplacé a été purgé. Il convient donc donc d'exécuter les commandes suivantes pour y remettre une adresse IP et l'allumer (pensez également que l'ensemble des routes y faisant référence ont été supprimées): | Comme expliqué plus haut, la configuration de l'interface déplacé a été purgé. Il convient donc donc d'exécuter les commandes suivantes pour y remettre une adresse IP et l'allumer (pensez également que l'ensemble des routes y faisant référence ont été supprimées): | ||
| Ligne 125 : | Ligne 129 : | ||
==Mise en place== | ==Mise en place== | ||
Je ne vais détailler les étapes car en dehors de la partie sur les ''vti'' (d'on la commande idoine est limpide de clarté), tout | Je ne vais pas détailler les étapes car en dehors de la partie sur les ''vti'' (d'on la commande idoine est limpide de clarté), tout a été expliqué et rien n'est fondamentalement incompréhensible à la lecture. | ||
===R1=== | ===R1=== | ||
| Ligne 168 : | Ligne 172 : | ||
ipsec restart | ipsec restart | ||
ipsec | ipsec up R1-vers-R2 | ||
===R2=== | ===R2=== | ||
| Ligne 211 : | Ligne 215 : | ||
ipsec restart | ipsec restart | ||
ipsec up R2-vers-R1 | |||
ipsec status | ipsec status | ||
| Ligne 237 : | Ligne 242 : | ||
===Évolution=== | ===Évolution=== | ||
On peut imaginer pour la suite mettre d'un coté un couple de ''veth'' avec le routage qui va bien pour permettre à un des deux | On peut imaginer pour la suite mettre d'un coté un couple de ''veth'' avec le routage qui va bien pour permettre à un des deux réseaux d'accéder à Internet ou à n'importe quel réseaux via le tunnel chiffré. L'utilisation de [[vxlan|VXLAN]] peut également être imaginé en remplacement des ''VLAN''. | ||
===Sources de la section=== | ===Sources de la section=== | ||
* https://vincent.bernat.im/fr/blog/2017-vpn-ipsec-route | * https://vincent.bernat.im/fr/blog/2017-vpn-ipsec-route | ||
* https://security.stackexchange.com/questions/10514/is-there-a-difference-between-a-vti-and-a-regular-vpn-tunneling-process | * https://security.stackexchange.com/questions/10514/is-there-a-difference-between-a-vti-and-a-regular-vpn-tunneling-process | ||
Dernière version du 26 février 2020 à 14:00
Les espaces de noms réseaux (network namespace) sous Linux permettent de cloisonner un ensemble applicatif relatif aux réseaux. Toute interface, service, paquet, trame... appartenant au même espace de noms sont isolés des éléments appartenant à un autre, au même titre que si ces éléments avaient été sur des machines différente. C'est le concept utilisé pour faire des conteneurs sous Linux afin de garantir une isolation plus poussé qu'un simple chroot.
Toutefois, un espace de noms réseau peut communiquer avec d'autres espaces si ils sont liés par une interface veth.
Les bases
L'ensemble des étapes de cette section sont a effectués sur la même machine. Utilisez un PC avec 2 interfaces réseau (un adaptateur USB/Ethernet fera l'affaire). Vous pouvez y connecter des clients pour bien comprendre les interactions entre les espaces de noms.
J'utilise une Debian 9 pour la documentation. Le paquet iproute2 est nécessaire pour pouvoir suivre ce qui suit.
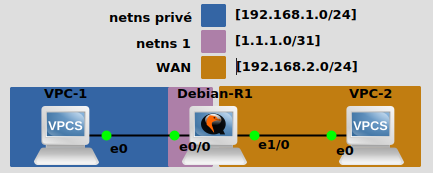
Je me réfère à ce schéma pour cette section.
Création d'un espace de noms réseau
Création
ip netns add privé
Listage
ip netns list
est équivalent à
ls /var/run/netns
ASTUCE
Par défaut sous Linux, tout est exécuté dans un espace de noms nommé 1 et qui n'apparais pas dans le listage. Cette information sera utile pour la suite.Suppression
ip netns del privé
Si nous en avons créés plusieurs, nous pouvons tous les supprimer avec les commandes suivantes:
- Avec une version d'iproute2 récente:
ip -all netns delete - Avec une ancienne version:
ip netns | xargs -I {} ip netns delete {}
Pour le moment, notre espace de noms ne contient rien, il ne sert donc à rien. Nous allons voir comment l'approvisionner pour cloisonner des interfaces.
Utilisation
Provisionnement d'une interface
ip link set netns privé dev eth0
Vous constatez avec un ip l que votre interface eth0 a disparue. Elle se trouve désormais dans l'espace de noms.
INFORMATION
Le fait de déplacer une interface réseau d'un espace de nom à un autre a pour effet de purger sa configuration au même titre qu'unip a f eth0. Il faudra donc penser à reconfigurer l'adressage et l'allumage de cette interface.Exécution d'une commande
Pour interagir avec notre espace de noms privé, il faut entrer des commandes dans celui-ci comme s'il s’agissait d'un shell à par-entière. Nous allons lister la configuration des interfaces de notre espace de noms avec ceci:
ip netns exec privé ip a
Paramètres:
- exec: exécute une commande dans l'espace de noms
- privé: espace de nom concerné par l'exécution (noté PID dans les pages de man)
- ip a: Commande que l'on aurai tapé normalement pour lister la configuration des interfaces réseaux
Il est également possible d'entrer dans l'espace de nom pour y exécuter les commandes standards de façon tout à fait normal (sorte de chroot) avec la commande suivante:
nsenter --net=/var/run/netns/privé
Note: la commande exit ou le traditionnel <ctrl>+<d> permettent d'en sortir.
Comme expliqué plus haut, la configuration de l'interface déplacé a été purgé. Il convient donc donc d'exécuter les commandes suivantes pour y remettre une adresse IP et l'allumer (pensez également que l'ensemble des routes y faisant référence ont été supprimées):
ip netns exec privé ip a a 192.168.1.254/24 dev eth0 ip netns exec privé ip l set eth0 up
À ce stade vous pouvez tenter un ping entre vos deux interfaces (configurez correctement le niveau 3 OSI bien sûr, c'est pas magique). Vous constaterez que les deux réseaux ne parviennent pas à se joindre bien qu'ils soit sur la même machine physique (il n'y a d'ailleurs pas de routes directement connectés pour joindre ces réseaux). Il en va de même pour les clients connectés aux deux extrémités (un sur l'interface dans privé et l'autre dans 1).
Dé-provisionnement d'une interface
ip netns exec privé ip link set eth0 netns 1
Note: c'est ici que le nom de l'espace de noms par défaut de Linux nous est utile.
Intercommunication avec les veth
Une interface veth est une interface fonctionnant par paire qui va nous servir à communiquer d'un espace de noms à un autre.
Création
ip link add vers_privé type veth peer name vers_1
Nous avons 2 interfaces supplémentaires nommées vers_privé et vers_1. Ces deux interfaces sont liées. Tout paquets envoyé vers l'une sortira par l'autre. Il va donc falloir envoyer une de ces interfaces dans notre espace de noms privé et laisser l'autre dans 1.
Provisionnement
ip link set vers_1 netns privé
Désormais, notre interface vers_1 trône aux coté d'eth0 dans privé. On peux entrer cette série de commande pour réaliser une communication inter-espace de noms:
# Configuration des interfaces dans "privé"
ip netns exec privé ip a a 192.168.1.254/24 dev eth0
ip netns exec privé ip l set eth0 up
ip netns exec privé ip a a 1.1.1.0/31 dev vers_1
ip netns exec privé ip l set vers_1 up
ip netns exec privé ip r a default via 1.1.1.1
# Configuration des interfaces dans "1"
ip a a 1.1.1.1/31 dev vers_privé
ip r a 192.168.1.0/24 via 1.1.1.0
ip a a 192.168.2.254/24 dev eth1
ip l set eth1 up
La communication entre VPC-1 et VPC-2 peut être vérifié par la commande suivante sur VPC-1
ping 192.168.2.1
Suppression
ip link del vers_privé type veth peer name vers_1
Note: Ceci a pour effet de supprimer les deux interfaces et ceux, dans tout les espaces de noms où elles sont présentes.
Utilité
En l'état, la chose parait bien peut utile mais le concept peut être étendu à l'élaboration d'un LAB (pourquoi ne pas créer notre propre GNS3 ?), la production où certains éléments doivent être isolé du reste sans utiliser de virtualisation ou bien à des fins de tests...
À titre d'exemple, les espaces de noms réseaux m'ont permit de tester 2 cartes réseaux 10gbps sur la même machine en m'assurant que les paquets passaient bien par le câble et non par le bus PCIe (quand on a qu'une seule carte mère à disposition, ça dépanne).
Sources de la section
- http://man7.org/linux/man-pages/man8/ip-netns.8.html
- http://ask.xmodulo.com/remove-network-namespaces-linux.html
- https://blog.scottlowe.org/2013/09/04/introducing-linux-network-namespaces/
Implémentations concrètes
Passerelle IPSec
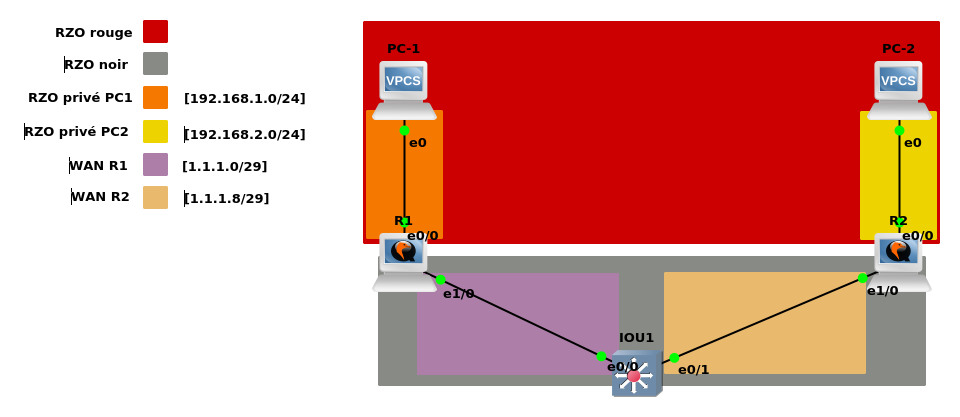
Une implémentation concrète du cloisonnement apporté par les espaces de noms est le cas d'une passerelle IPSec.
Imaginons que nous souhaitons faire communiquer deux réseaux à travers un tunnel IPSec comme dans la documentation déjà parue sur le sujet mais que l'usage des VLAN ne soit pas désiré. Nous souhaitons tout de même que les clients du LAN privé ne puissent pas faire autrement que de passer par le VPN pour accéder aux autres réseaux (d'on Internet si voulu). Avec les espaces de noms réseaux et les virtual tunnel interfaces (VTI), cette isolation pourras être effectuée et le couple encapsulation/décapsulation sera exécuté dans un espace de noms différent, ce qui assure un cloisonnement étanche en plus de ne pas avoir à ce faire chier avec les politiques de sécurité IPSec (qui dés que l'on sort du cadre pair à pair deviennent un enfer à gérer). Et cerise sur le gâteau, plus besoin de se faire chier à baisser le MTU des clients pour transférer des fichiers ! Le PMTUD fait son travail dans cette configuration.
Présentation
Pour ce LAB, j'utilise l'architecture suivante.
Les éléments nécessaires à sa mise en place ont été:
- GNS3
- Un disque qcow2 avec une Debian Stretch (9)
- Les utilitaires
iproute2etstrongswan - 2 MV exploitant une copie du disque qcow2 ainsi que 2 interfaces réseaux par machines
- Un routeur IOU ou non (j'ai utilisé un commutateur IOU avec des
no switchportsur les interfaces - 2 VPCS servant de clients pour effectuer les PING
Interfaces vti
Ce concept vient de l'entreprise Cisco et reprend notre façon de faire avec le tunnel de ce document. Partant du postulat que IPSec est un protocole ultra casse couille lorsqu'il s'agit de chiffrer des paquets routés, nous sommes plusieurs à penser qu'il est beaucoup plus simple d'utiliser des interfaces tunnels (qui elles sont autorisés par IPSec) et de faire transiter notre trafic réseau comme bon nous semble à l’intérieur en s’émancipant de la lourdeur d'IPSec.
Ainsi, les interface vti sont de bêtes tunnels GRE que l'on peut étiqueter (pour les gérer avec IPSec) et déplacer dans des espaces de noms différents.
Mise en place
Je ne vais pas détailler les étapes car en dehors de la partie sur les vti (d'on la commande idoine est limpide de clarté), tout a été expliqué et rien n'est fondamentalement incompréhensible à la lecture.
R1
ip netns add ipsec_rouge
ip tunnel add vti_rouge mode vti local 1.1.1.1 remote 1.1.1.10 key 6
ip link set netns ipsec_rouge dev vti_rouge
ip netns exec ipsec_rouge ip addr add 10.20.30.0/31 dev vti_rouge
ip netns exec ipsec_rouge ip link set vti_rouge mtu 1500
ip netns exec ipsec_rouge ip link set vti_rouge up
ip link set netns ipsec_rouge dev eth0
ip netns exec ipsec_rouge ip addr add 192.168.1.254/24 dev eth0
ip netns exec ipsec_rouge ip link set eth0 up
ip netns exec ipsec_rouge sysctl -w net.ipv4.ip_forward=1
ip netns exec ipsec_rouge ip r a default via 10.20.30.1
vim /etc/ipsec.conf
conn R1-vers-R2
left = 1.1.1.1
leftsubnet = 0.0.0.0/0
right = 1.1.1.10
rightsubnet = 0.0.0.0/0
authby = psk
mark = 6
auto = route
keyexchange = ikev2
keyingtries = %forever
ike = aes256gcm16-prfsha384-ecp384!
esp = aes256gcm16-prfsha384-ecp384!
mobike = no
vim /etc/ipsec.secrets
%any %any : PSK "MOT_DE_PASSE_TRES_SECRET"
ipsec restart ipsec up R1-vers-R2
R2
ip netns add ipsec_rouge
ip tunnel add vti_rouge mode vti local 1.1.1.10 remote 1.1.1.1 key 6
ip link set netns ipsec_rouge dev vti_rouge
ip netns exec ipsec_rouge ip addr add 10.20.30.1/31 dev vti_rouge
ip netns exec ipsec_rouge ip link set vti_rouge mtu 1500
ip netns exec ipsec_rouge ip link set vti_rouge up
ip link set netns ipsec_rouge dev eth0
ip netns exec ipsec_rouge ip addr add 192.168.2.254/24 dev eth0
ip netns exec ipsec_rouge ip link set eth0 up
ip netns exec ipsec_rouge sysctl -w net.ipv4.ip_forward=1
ip netns exec ipsec_rouge ip r a default via 10.20.30.0
vim /etc/ipsec.conf
conn R2-vers-R1
left = 1.1.1.10
leftsubnet = 0.0.0.0/0
right = 1.1.1.1
rightsubnet = 0.0.0.0/0
authby = psk
mark = 6
auto = route
keyexchange = ikev2
keyingtries = %forever
ike = aes256gcm16-prfsha384-ecp384!
esp = aes256gcm16-prfsha384-ecp384!
mobike = no
vim /etc/ipsec.secrets
%any %any : PSK "MOT_DE_PASSE_TRES_SECRET"
ipsec restart ipsec up R2-vers-R1 ipsec status
Phase de test
À ce stade, la communication chiffrée est possible. Voici une procédure de test servant à vérifier le fonctionnement du tout.
Sur un des serveur IPSec
ip netns exec ipsec_rouge tcpdump -n -i any
Ici R1.
Ping du client rattaché à l'espace de noms vers le client d'en face
ping 192.168.2.1
Ici "VPC-1" vers "VPC-2".
Les paquets apparaissent en clair sur le tcpdump du serveur dans cet espace de noms.
Maintenant, exécutez la même commande dans l'espace de noms par défaut (le réseau noir) et refaites le ping, vous ne voyez plus que des paquets esp (donc chiffrés).
Sur un des serveur IPSec
tcpdump -n -i any
Ici R1.
Ping du client rattaché à l'espace de noms vers le client d'en face
ping 192.168.2.1
Ici "VPC-1" vers "VPC-2".
Évolution
On peut imaginer pour la suite mettre d'un coté un couple de veth avec le routage qui va bien pour permettre à un des deux réseaux d'accéder à Internet ou à n'importe quel réseaux via le tunnel chiffré. L'utilisation de VXLAN peut également être imaginé en remplacement des VLAN.

{kind=link}
{kind=link}